在前一篇文章,我們介紹了 Logistic Regression 🚪傳送門,它的做法是用 Sigmoid function 把資料轉成機率,再依機率來進行分類。
這個方法比較直觀也容易理解,它只要能把不同類別大致分開就可以了。就好比你想把兩群人分開,只要隨便畫條線「剛好分開」就行了。
但是在資料很複雜、分布不規則時,這條隨便畫的線可能會離資料點太近,分類結果就容易出錯。
於是,今天我們要介紹另一個更嚴謹的畫線高手 — Support Vector Machine(SVM)。SVM 的目標不只是把不同類別分開,它還會去拉開類別之間的距離。可以想像成在分兩群人時,它會刻意拉出一個 安全距離,讓兩群人之間有一個緩衝空間,確保分類不會混在一起。
那 SVM 到底是怎麼做到的呢?我們就一起來看一下它的計算原理,最後再動手做一點實作練習吧~~
SVM 主要有四個核心概念:
要用一條線(Decision Boundry)把資料分成兩類,可以有很多種分法。但 SVM 追求的不只是把資料分開,而是選擇一條 「讓兩類之間距離最大」 的邊界。所以 SVM 目標是讓不同類別的資料之間拉出 最大間隔(Max Margin)。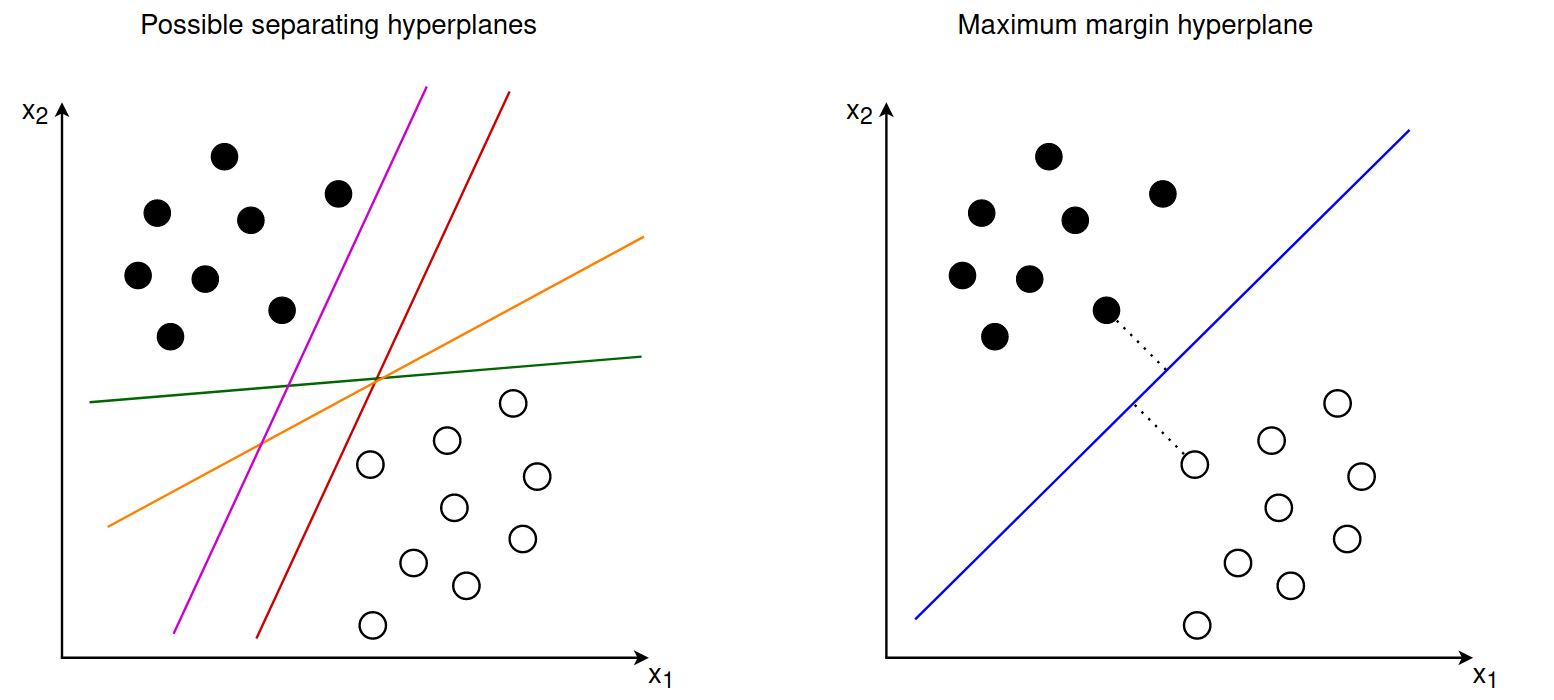
圖片來源:https://www.inovex.de/de/blog/support-vector-machines-guide/
決定最大間隔的並不是所有資料點,而是只有離邊界最近的那些點會影響 SVM 的決策線。這些關鍵的資料點就稱為 支持向量(Support Vectors)。
雖然 SVM 盡力畫出有最大間隔的決策線,但它還是允許一定程度的錯誤。它會透過 懲罰參數 𝐶 來控制容忍程度。
透過調整 𝐶 值,就是在 「準確度」 跟 「泛化能力」 之間找平衡~
有時資料會非常複雜,呈現 「線性不可分」 的狀態,也就是說用一條直線沒辦法切開,如下圖。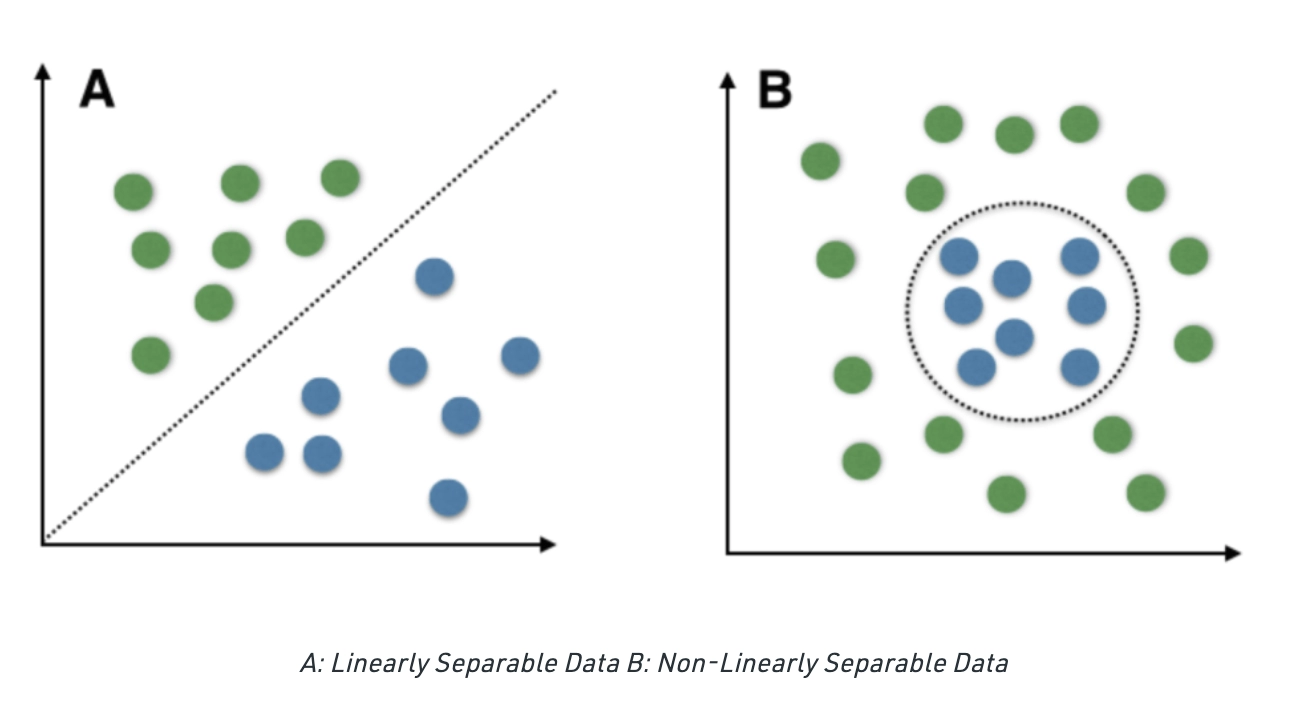
圖片來源:https://www.naukri.com/code360/library/linear-vs-non-linear-classification
SVM 有個神奇的功能可以解這題,叫做 核技巧(Kernel Trick)。這個做法是把資料投影到更高維的空間。讓原本聚成一團的資料,在新空間中可以被一條線分開。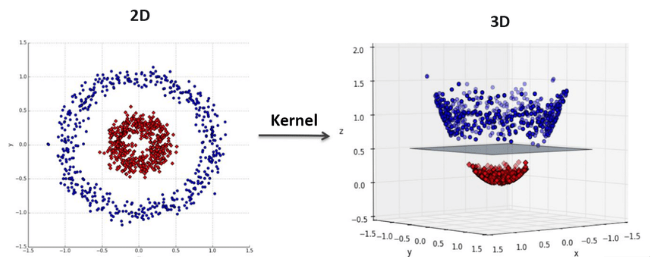
圖片來源:https://medium.com/@Suraj_Yadav/what-is-kernel-trick-in-svm-interview-questions-related-to-kernel-trick-97674401c48d
以下是三種常見的核函數:
線性核(Linear Kernel):最簡單的核函數,就是直接在原始特徵空間中找一條超平面分開資料。
多項式核(Polynomial Kernel):把原始資料映射到高維的多項式空間,讓原本線性不可分的資料,可以在高維空間用超平面分開。
RBF 核/高斯核(Radial Basis Function/Gaussian Kernel):RBF 核會把每個資料點轉換成一個「高維的能量場」。
最終在這個高維空間中找一個平面,把不同類別的「能量雲」分開。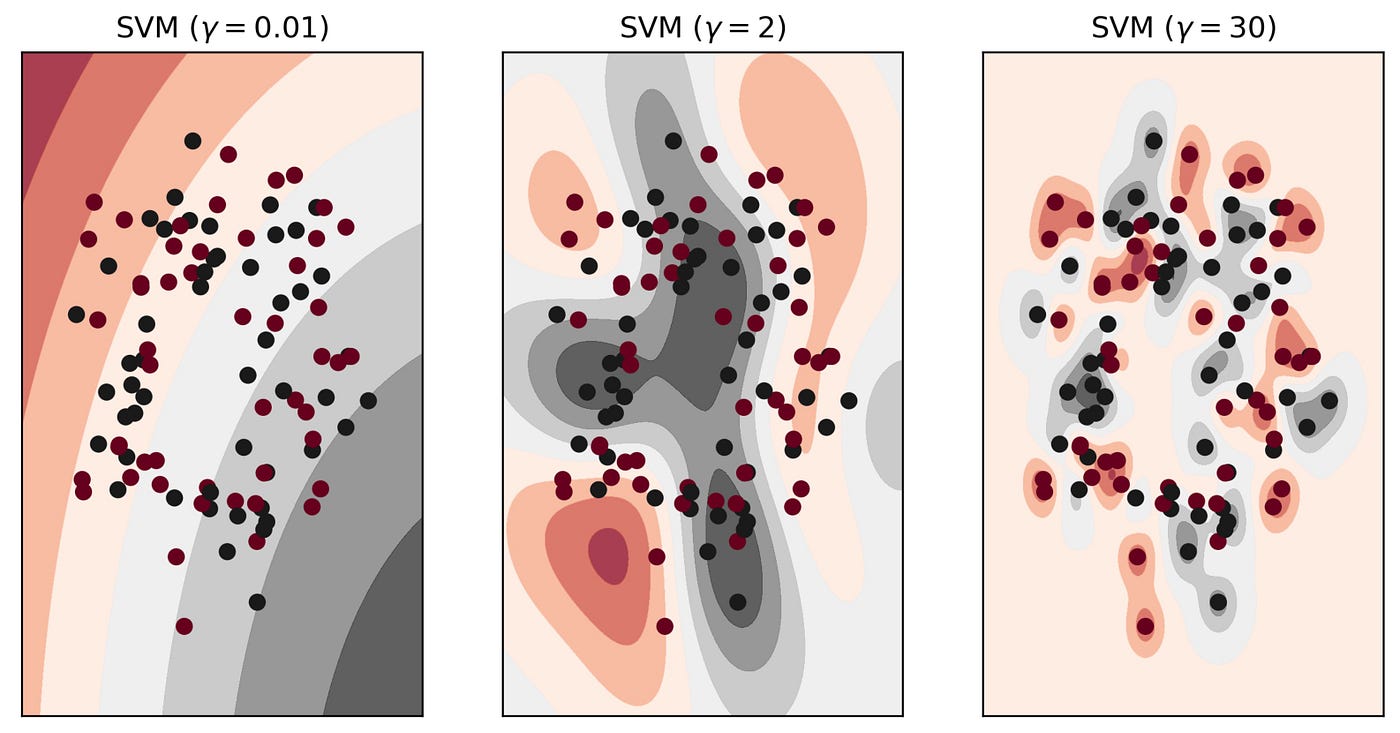
1. 前置預備(詳細步驟分解可以參考這篇 Naive Bayes)
import kagglehub
import pandas as pd
import os
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import TfidfVectorizer
# 讀取資料
path = kagglehub.dataset_download("ibrahimqasimi/imdb-50k-cleaned-movie-reviews")
csv_path = os.path.join(path, "IMDB_cleaned.csv")
df = pd.read_csv(csv_path)
# 資料劃分
X = df["cleaned_review"]
y = df["sentiment"]
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# 特徵轉換
vectorizer = TfidfVectorizer(stop_words="english", max_features=5000)
X_train_vec = vectorizer.fit_transform(X_train)
X_test_vec = vectorizer.transform(X_test)
2. SVM 模型訓練與評估
kernel 可選:linear, rbf, poly, sigmoid
from sklearn.svm import SVC
# 建立模型
svm_model = SVC(kernel="rbf", random_state=42)
svm_model.fit(X_train_vec, y_train)
y_pred = svm_model.predict(X_test_vec)
# 評估
print("=== SVM ===")
print("Accuracy:", f"{accuracy_score(y_test, y_pred):.3f}")
print("Precision:", f"{precision_score(y_test, y_pred, pos_label='positive'):.3f}")
print("Recall:", f"{recall_score(y_test, y_pred, pos_label='positive'):.3f}")
print("F1 Score:", f"{f1_score(y_test, y_pred, pos_label='positive'):.3f}")
print("\n分類報告:\n", classification_report(y_test, y_pred))
# 混淆矩陣
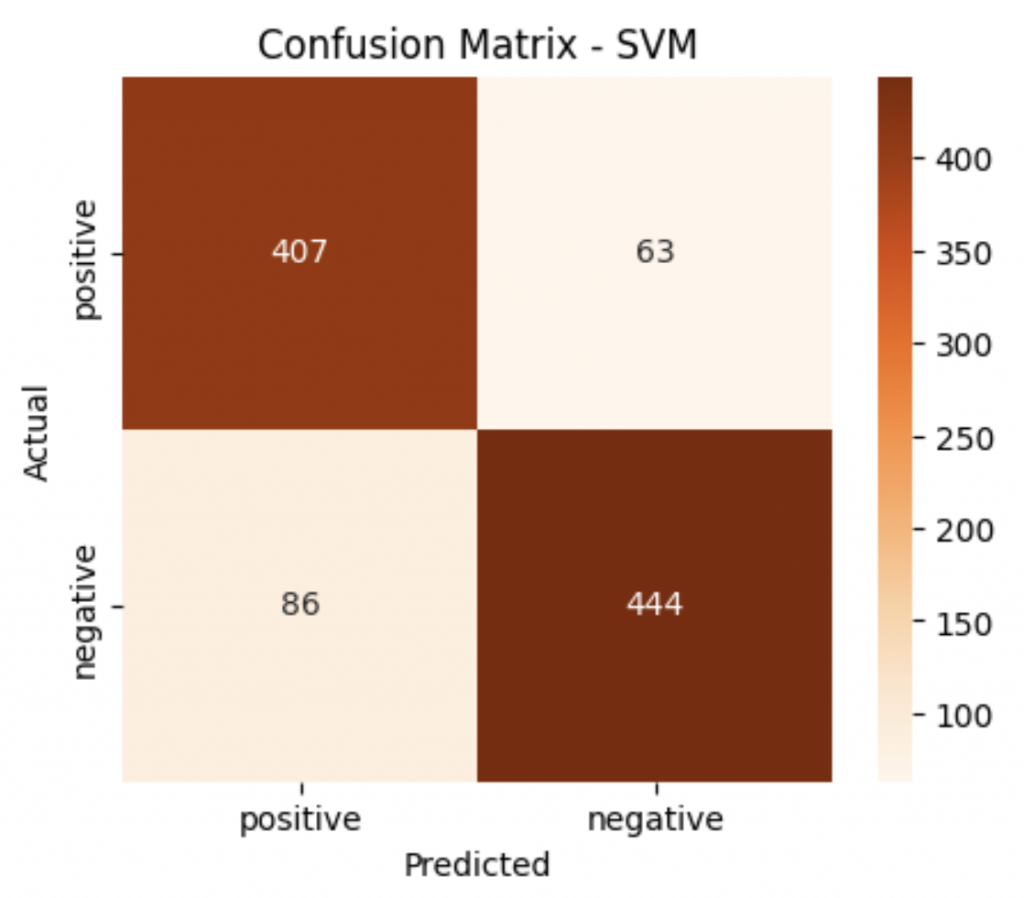
cm = confusion_matrix(y_test, y_pred, labels=["positive", "negative"])
plt.figure(figsize=(5,4))
sns.heatmap(cm, annot=True, fmt="d", cmap="Oranges",
xticklabels=["positive", "negative"],
yticklabels=["positive", "negative"])
plt.xlabel("Predicted")
plt.ylabel("Actual")
plt.title("Confusion Matrix - SVM")
plt.show()
=== SVM ===
Accuracy: 0.859
Precision: 0.828
Recall: 0.883
F1 Score: 0.855
分類報告:
precision recall f1-score support
negative 0.89 0.84 0.86 530
positive 0.83 0.88 0.85 470
accuracy 0.86 1000
macro avg 0.86 0.86 0.86 1000
weighted avg 0.86 0.86 0.86 1000
今天的 SVM 介紹到這裡,也代表我們的傳統機器學習方法告一段落啦~~
這幾天我們提到了機率統計模型、樹模型,以及線性分類模型。但是隨著資料越來越龐大也越來越複雜,單靠這些方法在計算量和模型的彈性上就會逐漸受限。
這時候我們就需要更強大的工具,能自動學習特徵、處理非線性,甚至更高維度的資料。於是,「深度學習」(Deep Learning) 就登場啦!!
明天我們會從 神經網路(Neural Networks) 開始,來看看它是如何模仿人腦的思考方式,接著一步步帶大家走進深度學習的世界~~~

